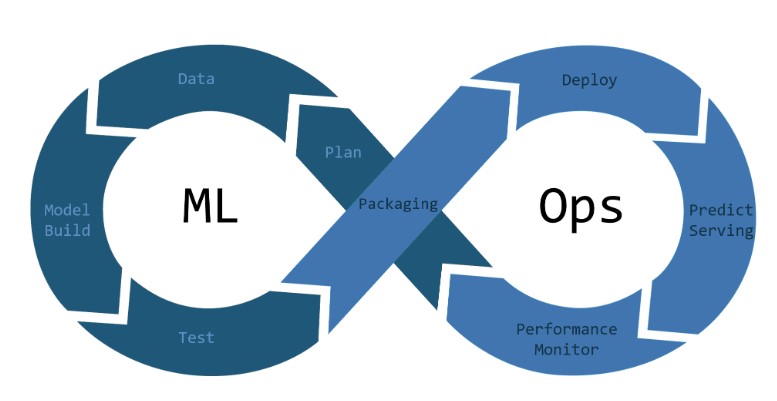
데이터 분석과 모델 운영의 핵심은 데이터 파이프라인을 자동화하여 평가, 적재, 모델 업데이트까지 원활하게 수행하는 것이다. 본 블로그에서는 통계 기반 평가와 머신러닝 모델 활용 평가를 자동으로 실행하고, 이를 바탕으로 MLOps를 통해 지속적으로 모델을 업데이트하는 전체 프로세스를 정리한다. 데이터 자동 처리 및 전처리 파이프라인 구축데이터 파이프라인 자동화 데이터 파이프라인 자동화이전 블로그에서는 데이터 필터링과 스케줄링을 통해 건강 평가를 수행하는 자동화된 데이터 파이프라인을 구축하는 방법을 살펴보았다. 이번에는 스크립트를 실행할 때 원시 데이터를 자동으wnsgud4553.tistory.com 원시 데이터를 자동으로 수집 및 전처리하여 분석이 가능한 형태로 변환.distribute_by_applica..