K-means 클러스터링은
- 비지도 학습(Unsupervised Learning) 알고리즘으로,
- 사용자가 미리 정한 K개의 클러스터 수를 기준으로
- 데이터를 자동으로 K개의 그룹으로 묶는 방법입니다.
데이터에 정답(label) 이 없는 상태에서
서로 비슷한 데이터끼리 묶는 것이 핵심 목적입니다.
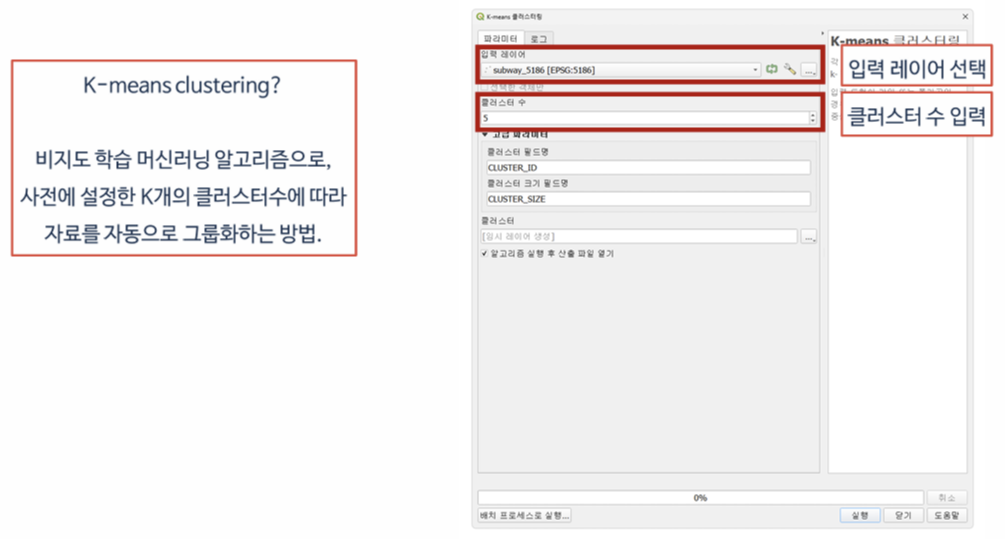
1. QGIS에서 K-means 클러스터링 실행 흐름
QGIS에서 K-means를 실행하면 다음 과정을 거칩니다.
1️⃣ 입력 레이어 선택
- 예: 지하철 역사 위치(점 데이터)
2️⃣ 클러스터 수(K) 입력
- 예: K = 5
3️⃣ 알고리즘 실행
실행 결과로 속성 테이블에 새로운 필드가 추가됩니다.
- CLUSTER_ID
→ 각 객체가 어느 클러스터에 속하는지 나타내는 번호 - CLUSTER_SIZE
→ 해당 클러스터에 몇 개의 객체가 포함되어 있는지\

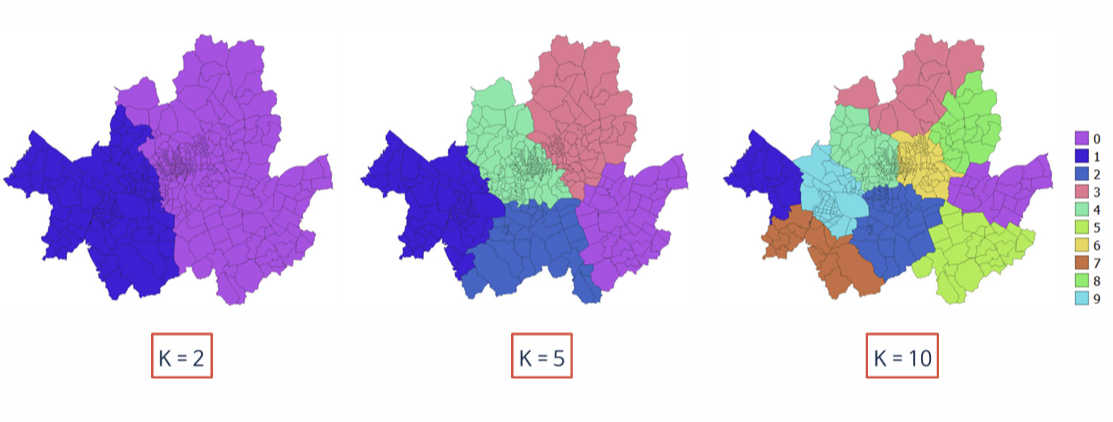
2. K 값에 따라 결과는 어떻게 달라질까?
K-means의 가장 중요한 특징은
👉 K 값에 따라 결과가 완전히 달라진다는 점입니다.
- K = 2
→ 매우 거친 그룹화 (큰 덩어리 2개) - K = 5
→ 적절한 수준의 공간적 분리 - K = 10
→ 세밀하지만 과도하게 쪼개질 수 있음
✔️ 따라서 K 선택은 분석 목적에 따라 결정해야 합니다.

3. 공간 데이터에서의 K-means 활용
공간 데이터(GIS)에 K-means를 적용하면,
- 행정구역
- 생활권
- 서비스 권역
- 수요 패턴 지역
등을 객관적인 기준으로 구분할 수 있습니다.
예를 들어,
- 서울시 행정동을 K-means로 묶으면
→ 유사한 공간 특성을 가진 지역 그룹을 도출할 수 있습니다.
정리하면
- K-means는 사전에 정한 K 값을 기준으로 데이터를 그룹화하는 비지도 학습 기법
- QGIS에서는 실행 시 CLUSTER_ID, CLUSTER_SIZE 필드가 자동 생성됨
- K 값이 작을수록 거칠고, 클수록 세밀한 분류
- 공간 분석에서는 지역 유형화·권역 분석에 매우 유용
K-means는 “몇 개로 나눌지(K)”를 정하고, 그 기준에 따라 데이터를 가장 비슷하게 묶는 방법이다.
'공간 분석 > 공간 분석 기초' 카테고리의 다른 글
| QGIS Python 콘솔로 공간 처리 알고리즘 파악하기 (0) | 2026.02.28 |
|---|---|
| QGIS에서 유효하지 않은 객체 처리 설정 방법 (0) | 2026.02.28 |
| QGIS 필드 재작성(Refactor Fields)이란? (0) | 2025.12.14 |
| 필드 계산기 사용 (0) | 2025.12.13 |
| 위치에 따른 속성 결합 (0) | 2025.12.13 |