실시간 데이터 처리는 “데이터가 발생하는 순간”부터
즉시 수집·처리·저장·활용까지 이어지는 구조입니다.
배치 처리와 달리, 일정 시간 후 모아서 분석하는 것이 아니라
이벤트가 발생하는 즉시 반응하는 것이 핵심입니다.
1. 실시간 수집 단계
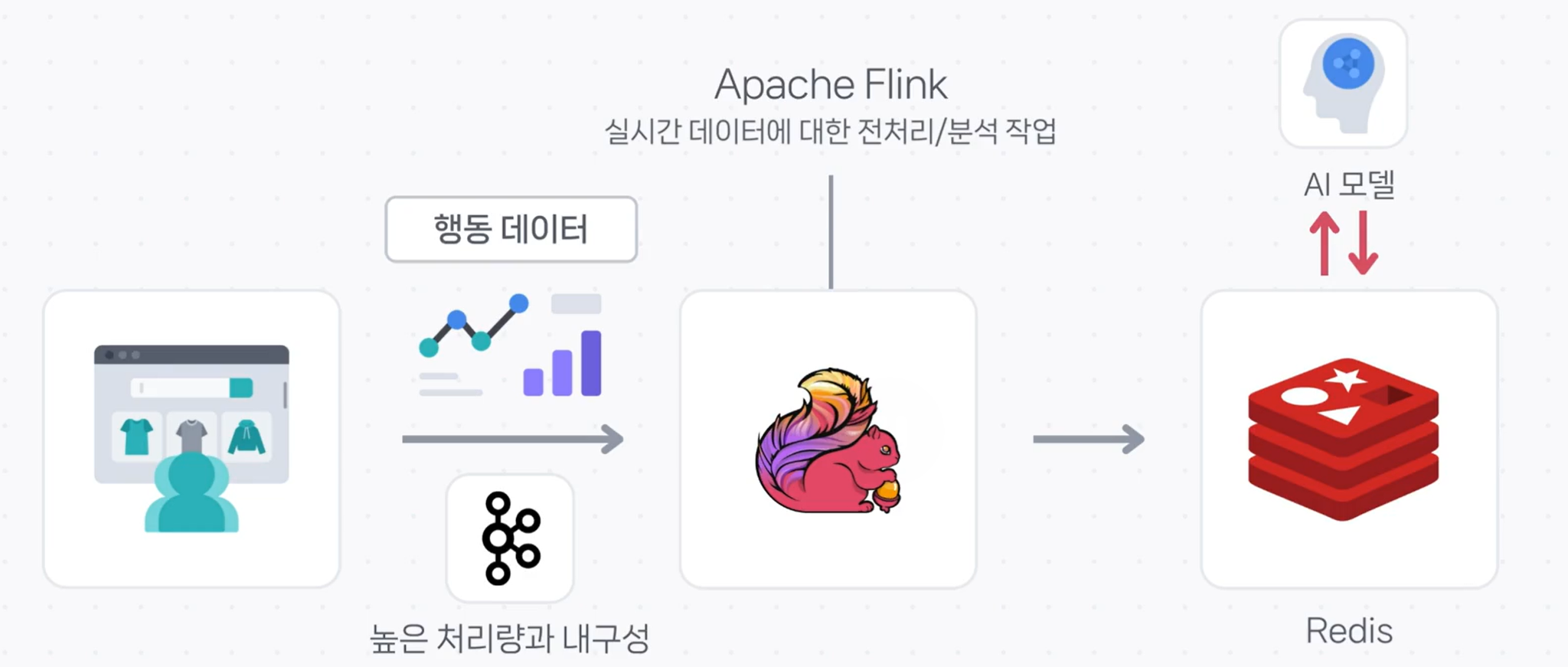
사용자 행동 데이터, 거래 데이터 등 이벤트가 발생하면
메시지 브로커를 통해 즉시 수집됩니다.
대표적으로:
- RabbitMQ
- Apache Kafka
이 단계는 데이터가 흘러들어오는 “입구” 역할을 합니다.
높은 처리량과 장애 대응 능력이 중요합니다.
비유하면, 끊임없이 들어오는 택배를 받아주는 물류 허브입니다
2. 실시간 처리 단계
수집된 데이터는 스트리밍 엔진에서 즉시 가공됩니다.
대표적으로:
- Apache Flink
- Apache Spark (Spark Streaming)
여기서 집계, 필터링, 패턴 탐지, 이상 탐지 등이 수행됩니다.
대용량 데이터를 지연 없이 처리하는 것이 핵심입니다.
비유하면, 들어온 택배를 즉시 분류하는 자동화 설비입니다.
3. 실시간 저장 및 활용 단계
처리된 결과는 빠른 조회가 가능한 저장소에 적재됩니다.
대표적으로:
- Redis
- Elasticsearch
이 저장소는 대시보드, 검색, 알림 시스템, AI 모델과 연결되어
즉각적인 의사결정을 지원합니다.
예시:
- 실시간 이상 거래 감지 후 경고 알림
- 사용자 행동 기반 추천 모델 입력값 제공
비유하면, 분류된 택배를 바로 배송 차량에 싣는 단계입니다.
4. 정리
데이터 발생 → 메시지 브로커 수집 → 스트리밍 처리 → 고속 저장소 적재 → 즉시 활용
실시간 데이터 처리는 “발생 즉시 수집·처리·저장·활용”까지 이어지는 구조로, 지연 없이 의사결정을 가능하게 하는 데이터 아키텍처입니다.

'데이터 엔지니어링(정리)' 카테고리의 다른 글
| ETL vs ELT? (0) | 2026.02.19 |
|---|---|
| ETL(Extract, Transform, Load)의 구조 개념 (0) | 2026.02.19 |
| 데이터 파이프라인 구조와 운영 전략: 수집부터 모니터링까지 (0) | 2026.02.19 |
| 배치 처리와 스트리밍 처리란 (0) | 2026.02.19 |
| OLTP와 OLAP의 개념 차이와 역할 구분 (0) | 2026.02.18 |