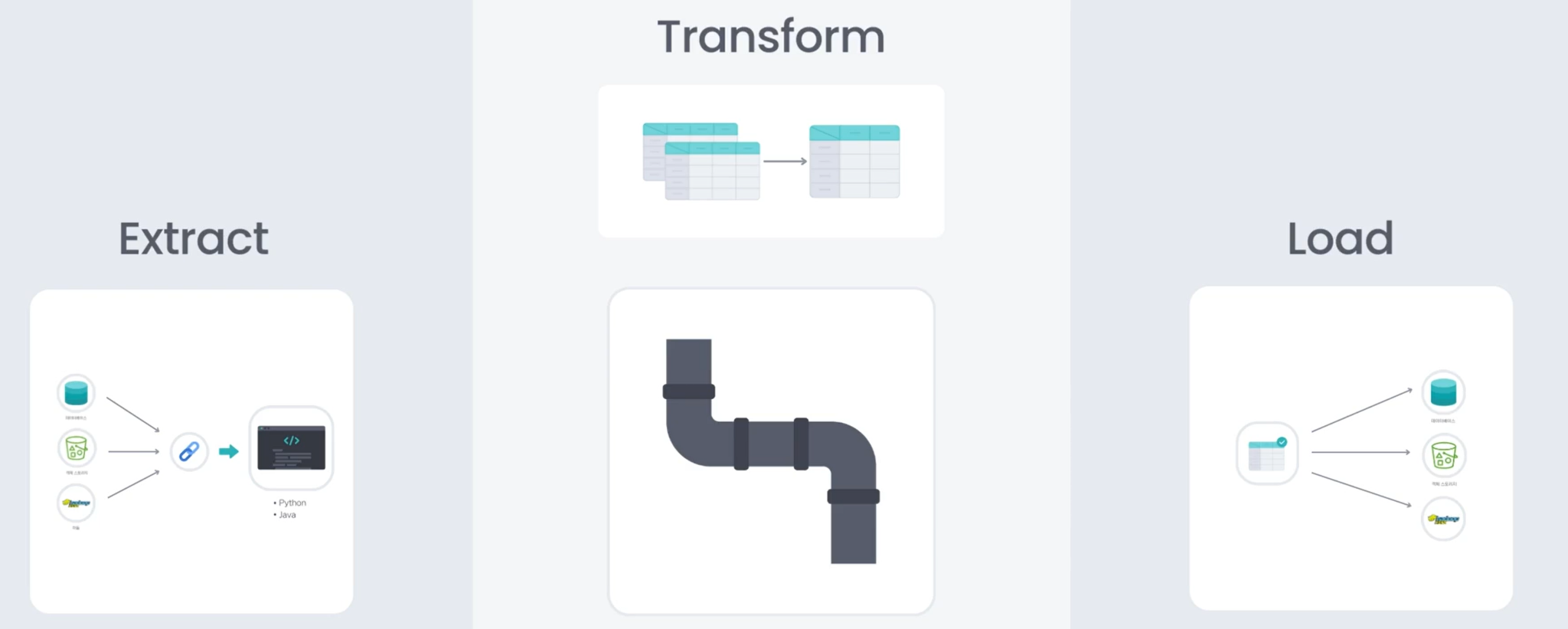
ETL은 데이터를 수집(Extract) → 변환(Transform) → 저장(Load) 하는 일련의 흐름을 의미합니다.
데이터 파이프라인의 가장 기본적인 구조로, 분석 환경을 만들기 위한 출발점입니다.
1. Extract (수집 단계)
데이터 소스나 저장소로부터 데이터를 가져오는 과정입니다.
데이터베이스, 객체 스토리지(S3 등), Hadoop, 외부 API 등 다양한 원천에서 데이터를 읽어옵니다.
이 단계는 데이터 파이프라인의 시작점에 해당합니다.
비유하면, 여러 창고에서 재료를 꺼내 한곳에 모으는 과정입니다.
2. Transform (처리 및 변환 단계)
수집된 데이터를 분석 및 저장에 적합한 형태로 정제·가공하는 단계입니다.
이상치 제거, 결측치 처리, 형식 통일뿐 아니라
집계(GROUP BY), 조인(JOIN), 스키마 변경 등 데이터의 내용과 구조를 변경합니다.
Spark, Flink, Pandas 같은 처리 엔진을 사용할 수 있습니다.
비유하면, 재료를 손질하고 요리 목적에 맞게 가공하는 과정입니다.

3. Load (저장 단계)
변환이 완료된 데이터를 최종 저장소로 적재하는 단계입니다.
Data Warehouse, Data Lake, DB, 분석 시스템 등
목적에 맞는 저장소에 데이터를 저장합니다.
이 단계에서는 저장소와의 연결을 수립하고
데이터를 적재(Insert/Append/Overwrite)합니다.
비유하면, 완성된 요리를 그릇에 담아 제공하는 과정입니다.
ETL은 데이터를 가져오고(Extract), 분석 가능하게 가공한 뒤(Transform), 최종 저장소에 적재하는(Load) 데이터 파이프라인의 기본 구조입니다.
'데이터 엔지니어링(정리)' 카테고리의 다른 글
| 실시간 데이터 처리 아키텍처: 수집부터 분석·활용까지의 흐름 (0) | 2026.02.19 |
|---|---|
| ETL vs ELT? (0) | 2026.02.19 |
| 데이터 파이프라인 구조와 운영 전략: 수집부터 모니터링까지 (0) | 2026.02.19 |
| 배치 처리와 스트리밍 처리란 (0) | 2026.02.19 |
| OLTP와 OLAP의 개념 차이와 역할 구분 (0) | 2026.02.18 |