MLflow에서 실험을 추적할 때 일반적으로 with mlflow.start_run(): 구문을 사용하지만, 반드시 end_run()을 명시적으로 호출하지 않아도 된다.
with 블록을 사용하면 실행이 끝날 때 자동으로 end_run()이 호출되므로 별도로 관리할 필요가 없다.
이 방식은 코드의 가독성을 높이고, 실험을 자동으로 종료할 수 있어 편리하다.
# Mlflow Sklearn을 활용해서 모델 및 메트릭 자동 기록!
'''
To do
use autolog() on mlflow
'''
mlflow.sklearn.autolog()
# 모델 초기화
n_estimator = 77
random_state = 2222
model = RandomForestClassifier(n_estimators=n_estimator, random_state=random_state)
# 모델 학습
model.fit(X_train, y_train)
# 테스트 데이터에 대한 예측
y_pred = model.predict(X_test)
# 정확도 계산
accuracy = accuracy_score(y_test, y_pred)
prf = precision_recall_fscore_support(y_test, y_pred, average='binary')
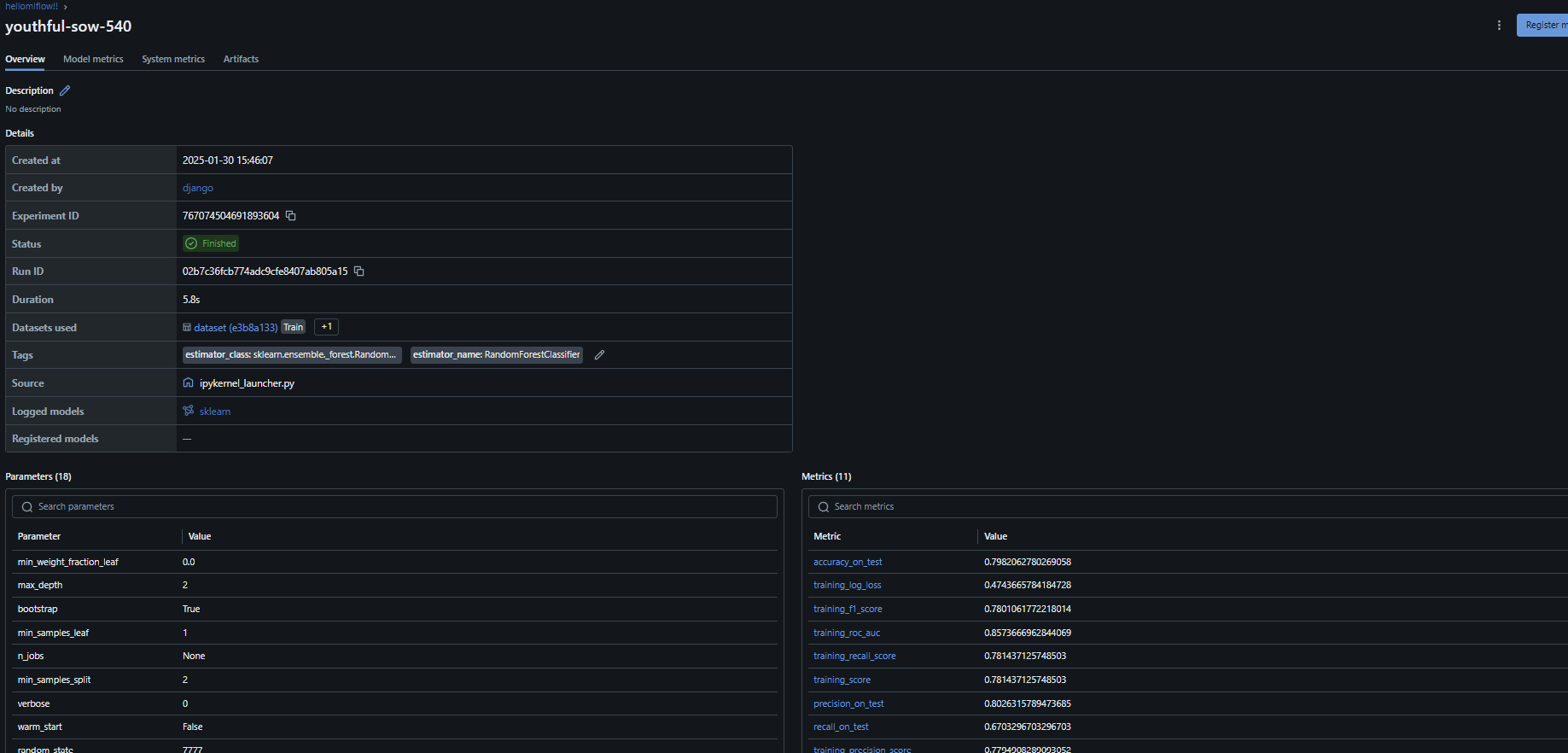
mlflow.sklearn.autolog()을 사용하면 Scikit-Learn 모델의 하이퍼파라미터, 메트릭, 모델 아티팩트 등을 자동으로 기록할 수 있다.
autolog()가 활성화된 상태에서 model.fit()을 호출하면, MLflow가 자동으로 n_estimators, random_state 같은 하이퍼파라미터와 학습된 모델을 로깅한다.
또한, predict()를 수행하고 성능 지표(accuracy, precision, recall, f1-score)를 계산하면, 이 정보도 MLflow에 기록 가능하다.
이 방식은 별도의 mlflow.log_param()이나 mlflow.log_metric()을 수동으로 호출할 필요 없이, 자동으로 로깅을 수행할 수 있어 코드가 간결해진다.
'''
To do
auto logging에서 수집되지 않는 정보 추가로 logging 하기
precision, recall, f1score, accuracy for test data set
'''
mlflow.sklearn.autolog()
with mlflow.start_run():
n_estimator = 400
random_state = 7777
max_depth = 2
model = RandomForestClassifier(n_estimators=n_estimator, random_state=random_state, max_depth=max_depth)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
prf = precision_recall_fscore_support(y_test, y_pred, average="binary")
mlflow.log_metric("precision_on_test", prf[0])
mlflow.log_metric("recall_on_test", prf[1])
mlflow.log_metric("f1score_on_test", prf[2])
mlflow.log_metric("accuracy_on_test", accuracy)
mlflow.sklearn.autolog()을 호출하면, 모델의 하이퍼파라미터 및 훈련 과정 정보가 자동으로 로깅된다.
하지만, autolog()는 모든 성능 지표를 자동으로 기록하지 않으므로, 추가적인 성능 메트릭(precision, recall, f1-score, accuracy)을 직접 로깅해야 한다.
autolog()가 자동으로 기록하지 않는 precision, recall, f1-score, accuracy 값을 mlflow.log_metric()을 사용해 개별적으로 저장.
"precision_on_test", "recall_on_test", "f1score_on_test", "accuracy_on_test" 등의 키 이름으로 저장하여 테스트 데이터 기준 성능을 추적 가능.