앞서 stack()과 unstack()으로 인덱스를 기준으로 데이터 구조를 전환하는 방법을 배웠습니다.
이번에는 melt()와 pivot()을 통해 컬럼을 기준으로 데이터 포맷을 자유롭게 변환해보겠습니다.
- melt() → Wide → Long 형태로 변환
- pivot() → Long → Wide 형태로 변환
이 두 함수는 데이터 시각화, 머신러닝 전처리, 분석 보고서 정리에 꼭 필요한 핵심 기능입니다.
예제 데이터 준비
import pandas as pd
df = pd.DataFrame({
'student': ['혜선', '종훈', '지웅'],
'math': [85, 90, 95],
'english': [80, 88, 92]
})
print(df)
Wide 포맷 (원본)
student math english
0 혜선 85 80
1 종훈 90 88
2 지웅 95 92
melt(): Wide → Long 변환
long_df = pd.melt(df, id_vars='student', var_name='subject', value_name='score')
print(long_df)🔹 출력 결과
student subject score
0 혜선 math 85
1 종훈 math 90
2 지웅 math 95
3 혜선 english 80
4 종훈 english 88
5 지웅 english 92수학, 영어 점수가 열에서 행으로 녹여져(long) 하나의 열로 정리됨
시각화나 그룹 분석 시 매우 유용한 포맷
pivot(): Long → Wide 변환
wide_df = long_df.pivot(index='student', columns='subject', values='score')
print(wide_df)🔹 출력 결과
subject english math
student
혜선 80 85
종훈 88 90
지웅 92 95 다시 원래처럼 과목별 컬럼을 가진 Wide 포맷으로 되돌림
pivot()은 index, columns, values 세 축을 지정해야 함
melt()에서 id_vars를 다중 선택
df = pd.DataFrame({
'name': ['혜선', '종훈'],
'year': [2023, 2023],
'math': [95, 88],
'english': [89, 92]
})
melted = pd.melt(df, id_vars=['name', 'year'], var_name='subject', value_name='score')
print(melted)✅ 출력
name year subject score
0 혜선 2023 math 95
1 종훈 2023 math 88
2 혜선 2023 english 89
3 종훈 2023 english 92name과 year가 식별자 역할을 하고, 나머지 열이 녹아내림
melt()를 사용할 때 컬럼이 많거나, **과목 외의 다른 데이터(예: 성별, 학년 등)**가 함께 있는 경우, 어떻게 처리되는지 이해하는 게 정말 중요하죠.
핵심 개념 정리
- id_vars는 "녹이지 말고 유지할 컬럼"
- value_vars는 (옵션) "녹일 컬럼을 명시적으로 지정할 수 있음"
- 아무 설정도 안 하면 id_vars 외의 모든 나머지 컬럼이 녹아내림
예제: 컬럼이 많은 경우
import pandas as pd
df = pd.DataFrame({
'student': ['혜선', '종훈'],
'gender': ['F', 'M'],
'grade': [3, 2],
'math': [90, 95],
'english': [85, 92],
'science': [88, 90]
})이 상태에서 pd.melt(df, id_vars=['student'])를 실행하면?
melted = pd.melt(df, id_vars=['student'])
print(melted)출력 결과:
student variable value
0 혜선 gender F
1 종훈 gender M
2 혜선 grade 3
3 종훈 grade 2
4 혜선 math 90
5 종훈 math 95
6 혜선 english 85
7 종훈 english 92
8 혜선 science 88
9 종훈 science 90
그런데 우리는 점수 컬럼만 녹이고, gender와 grade는 유지하고 싶다면?
pd.melt(df,
id_vars=['student', 'gender', 'grade'],
value_vars=['math', 'english', 'science'],
var_name='subject',
value_name='score')출력 결과:
student gender grade subject score
0 혜선 F 3 math 90
1 종훈 M 2 math 95
2 혜선 F 3 english 85
3 종훈 M 2 english 92
4 혜선 F 3 science 88
5 종훈 M 2 science 90
요약 정리

pivot() vs pivot_table() 차이점은?
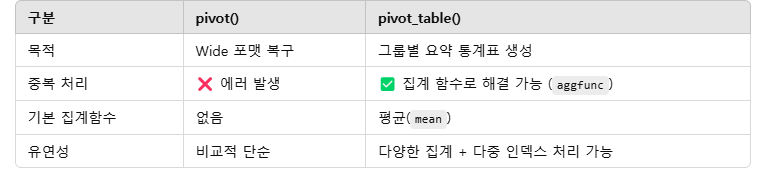
예시 비교
df = pd.DataFrame({
'student': ['혜선', '혜선', '종훈'],
'subject': ['math', 'math', 'math'],
'score': [95, 100, 90]
})
# pivot() ❌
# df.pivot(index='student', columns='subject', values='score') → ValueError
# pivot_table() ✅
pivoted = df.pivot_table(index='student', columns='subject', values='score', aggfunc='mean')
print(pivoted)
pivot()은 index + columns 조합이 유일해야 정상적으로 작동합니다
→ ValueError: Index contains duplicate entries, cannot reshape
동일한 index+column 조합이 중복되면 pivot()은 실패합니다.
✔️ 해결 방법
중복이 있을 가능성이 있다면 pivot_table()을 사용하세요.
자동으로 평균, 합계 등 원하는 방식으로 집계(aggregation) 해줍니다.
정리

실무 활용 팁
- melt()는 시각화 전 구조 변경에 필수
- pivot()은 데이터 요약 결과를 보기 좋게 재정렬할 때 유용
- 둘 다 Pandas에서 가장 자주 쓰이는 포맷 변환 도구 중 하나
- melt()는 원본 데이터를 Long format으로 정리할 때 유용
- 시각화나 그룹 통계 시, 분석 대상 컬럼만 녹이는 것이 일반적
- 컬럼 수가 많을수록 id_vars / value_vars는 꼭 명시하는 습관 들이기
'파이썬 > 데이터프레임 다루기' 카테고리의 다른 글
| 이터레이터 vs 제너레이터: 파이썬 반복의 핵심 이해하기 (0) | 2025.03.24 |
|---|---|
| Pandas groupby 완전 정복: 집계부터 고급 활용까지 (0) | 2025.03.24 |
| Pandas pivot_table() 완전 정복 (0) | 2025.03.24 |
| Pandas 멀티인덱스 다루기: stack()과 unstack() 정리 (0) | 2025.03.24 |
| Pandas에서 함수형 방식으로 데이터프레임 다루기 (0) | 2025.03.24 |