이번 글에서는 Docker Compose 기반 Airflow 환경에서
해양 센서 데이터를 시간 단위로 생성 → Raw 적재 시 품질 검증 → 일 단위 집계로 처리한 ETL 파이프라인 설계를 정리합니다.
특히 이 프로젝트의 핵심인 Raw 적재 단계의 품질 가드(Guard) 와
집계 DAG를 분리하고 FileSensor로 연결한 이유를 중심으로 설명합니다.
1. 전체 흐름을 먼저 보면
이 파이프라인은 복잡해 보이지만, 흐름은 단순합니다.
- 시간 단위 해양 센서 CSV 생성
- Raw 적재 시 중복·변경 여부 검사
- Raw 적재 시 Log 생성
- 검증된 데이터만 일 단위로 집계
중요한 점은 모든 처리를 하나의 DAG로 묶지 않았다는 것입니다.
각 단계는 역할이 다르기 때문에 DAG도 분리했습니다.
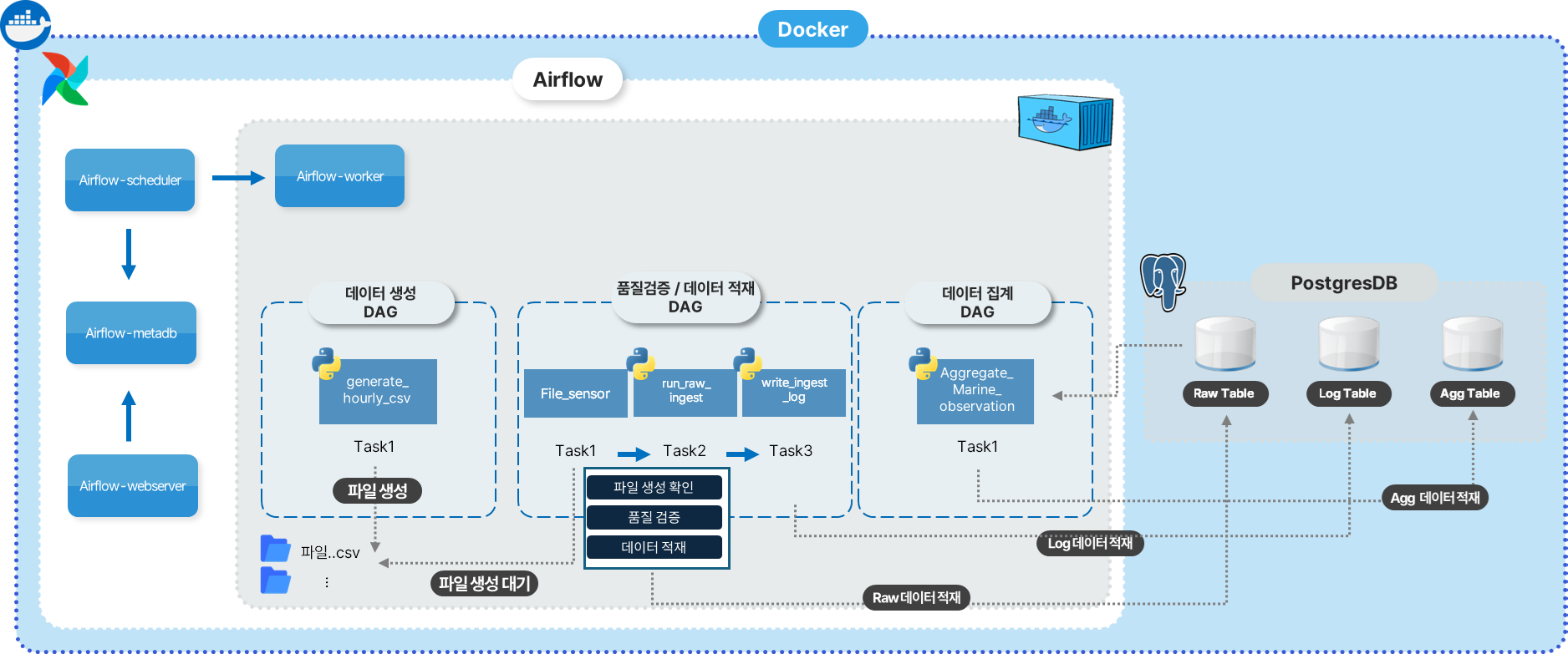
2. 시간 단위 데이터 생성 (데이터 생성 DAG)
가장 앞단에서는 해양 센서 관측 데이터를 시간 단위 CSV 파일로 생성합니다.
이 단계는 Airflow DAG로 관리됩니다.


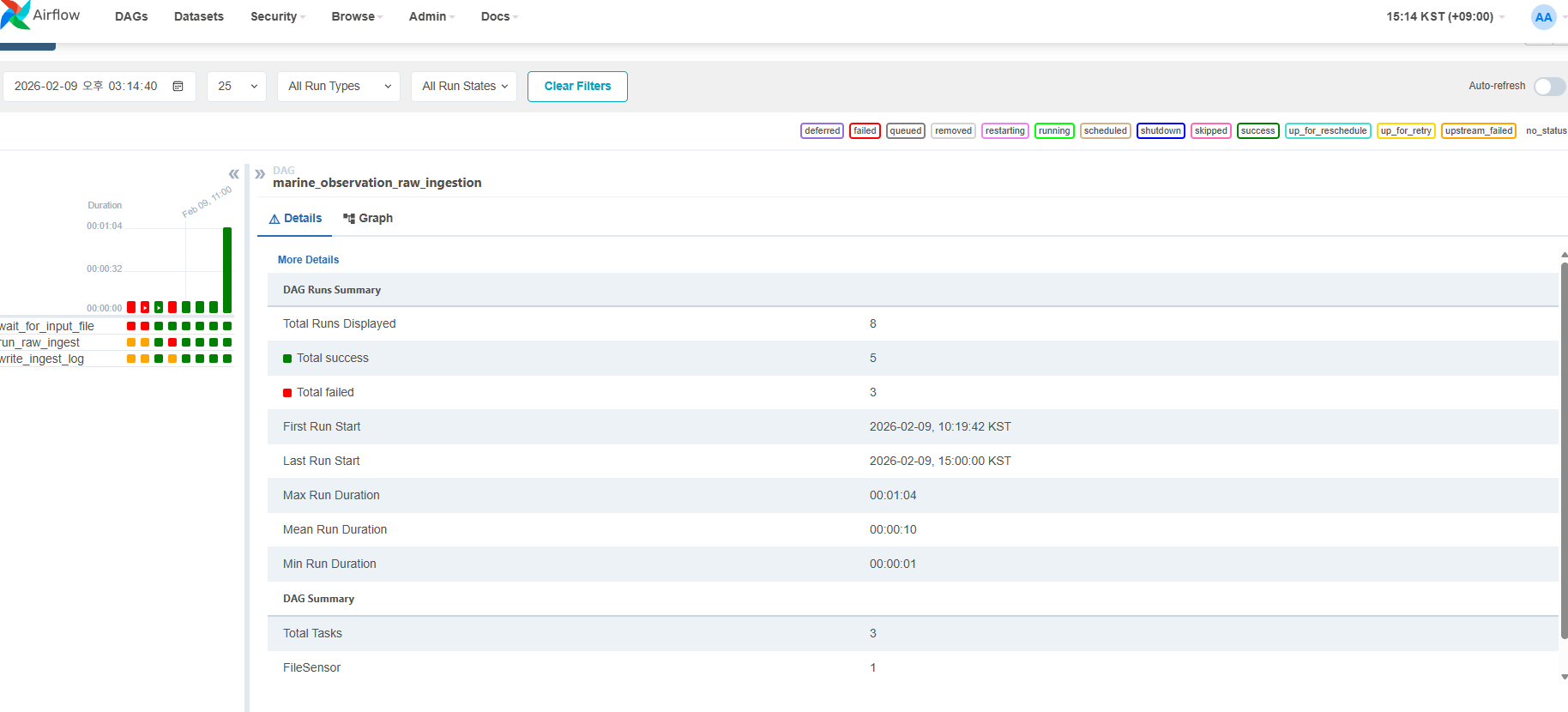
3. FileSensor의 역할: Raw 파일 도착 즉시 적재 (품질검증 및 데이터 적재 DAG)
FileSensor의 목적은 명확합니다.
Raw CSV 파일이 생성되는 즉시, Raw 테이블에 적재하기 위함
- 특정 시간에 실행하는 것이 아니라
- 파일이 존재하는 순간을 트리거로 삼습니다
이 구조를 선택한 이유는 다음과 같습니다.
- 불필요한 폴링이나 고정 스케줄 제거
- “데이터 중심” 실행 흐름 확보
비유하자면,
알람 시계에 맞춰 움직이는 것이 아니라
우편함에 편지가 들어오는 순간 바로 처리하는 구조입니다.
wait_for_file = FileSensor(
task_id = 'wait_for_input_file',
filepath=(
"/opt/airflow/data/marine_observation_"
"{{ (execution_date + macros.timedelta(hours=9)).strftime('%Y%m%d_%H') }}.csv"
),
poke_interval=60,
timeout=60 * 30,
mode="reschedule",
)4. Raw 적재의 핵심: 품질 가드(Guard) 로직 (품질검증 및 데이터 적재 DAG)
Raw 테이블은 모든 분석과 집계의 출발점입니다.
그래서 이 프로젝트에서는 Raw 적재 시 품질 검증을 필수 단계로 두었습니다.
- 같은 batch_id가 이미 적재된 경우
- 행 수가 다르면 실패
- 내용이 다르면 실패
- 행 수와 내용이 같으면 Skip
- 신규 batch라면 정상 적재
검증 기준은 단순하지만 명확합니다.
5. 왜 Skip과 Fail을 구분했을까?
같은 batch가 다시 들어오는 것은 정상적인 재실행 상황일 수 있습니다.
하지만 같은 batch인데 내용이 달라졌다면, 이는 데이터 파이프라인 관점에서 위험 신호입니다.
그래서 이 프로젝트에서는 다음처럼 명확히 나눴습니다.
- Skip: 이미 처리한 데이터를 다시 만난 경우
- Fail: 데이터 무결성이 깨졌다고 판단되는 경우
이 구분 덕분에,
문제가 생겼을 때 파이프라인이 조용히 지나가지 않고
의도적으로 멈추게 됩니다.
import pandas as pd
import hashlib
import psycopg2
from sqlalchemy import create_engine, text
from typing import Optional
from airflow.exceptions import AirflowSkipException
def guard_ingest_or_raise(
batch_id: str,
csv_path: str,
conn_uri: str
) -> None:
"""
batch_id 기준으로 중복 여부와 데이터 변경 여부를 판단한다.
- 이미 적재되었고 행 수가 같으면 SKIP
- 이미 적재되었고 행 수가 다르면 FAIL
- 신규 batch면 아무 것도 하지 않는다
"""
if not is_batch_ingested(batch_id, conn_uri):
return
prev_cnt = get_prev_row_count(batch_id, conn_uri)
curr_cnt = get_csv_row_count(csv_path)
if prev_cnt != curr_cnt:
raise ValueError("Row count changed for same batch_id")
prev_hash = get_prev_content_hash(batch_id, conn_uri)
curr_hash = compute_file_hash(csv_path)
if prev_hash != curr_hash:
raise ValueError("Content changed for same batch_id")
raise AirflowSkipException("Already ingested")
6. 집계는 “검증된 이후의 문제”
일 단위 집계는 Raw 적재 이후의 단계입니다.
하지만 이 글의 핵심은 집계 로직이 아니라,
집계가 신뢰할 수 있으려면, Raw가 먼저 신뢰 가능해야 한다
는 점입니다.
그래서 집계는 Raw 품질 가드가 통과된 데이터만을 대상으로 수행됩니다.
이 프로젝트는 해양 센서 데이터를 단순히 스케줄링한 것이 아니라,
Raw 파일 도착 즉시 적재하고,
변경된 데이터는 절대 조용히 지나가지 않도록 설계한 ETL 구조입니다.

7. ingest_log 테이블: “성공한 적재만 기록하는 최소 로그”
현재 ingest_log 테이블은 Raw 적재가 정상적으로 끝난 경우만 기록합니다.
즉, 이 테이블의 목적은 “모든 이벤트 기록”이 아니라,
어떤 batch가 실제로 Raw 테이블에 반영되었는지를 남기는 것입니다.
로그에 포함된 정보는 다음과 같습니다.
- table_name: 적재 대상 테이블
- batch_id: 시간 단위 배치 식별자
- ingest_start_time: 적재 시작 시각
- expected_record_count: CSV 기준 레코드 수
- ingest_status: 성공 여부
- content_hash: 파일 내용 해시
이 구조는 의도적으로 단순합니다.
실패한 경우의 상세 원인은 Airflow 로그가 담당하고,
ingest_log는 “이 데이터는 Raw에 들어갔다”라는 사실만 보증합니다.


8. 폴더 구조: 트리로 드러나는 데이터 흐름
project-root
├─ airflow
│ ├─ dags
│ │ ├─ marine_observation_raw_ingestion_dag.py
│ │ ├─ marine_observation_hourly_synthesis_dag.py
│ │ └─ marine_observation_daily_aggregation_dag.py
│ └─ docker-compose.yaml
│
├─ data
│ ├─ raw
│ │ └─ marine_observation_YYYYMMDD_HH.csv
│ └─ aggregation
│ └─ marine_observation_YYYYMMDD.csv
│
├─ src
│ ├─ synthesis
│ │ └─ hourly_generator.py
│ │
│ ├─ raw
│ │ ├─ loader.py
│ │ ├─ ingestion_guard.py
│ │ └─ log_writer.py
│ │
│ └─ analysis
│ └─ aggregation.py이 트리는 한눈에 다음 질문에 답합니다.
- 이 데이터는 어디서 만들어졌는가?
- Raw 적재 시 어떤 검증을 거치는가?
- 집계는 Raw 이후 어디서 수행되는가?
각 폴더는 자기 단계의 책임만 가집니다.
Raw 로직은 집계를 모르고,
집계 로직은 Raw 구현을 신경 쓰지 않습니다.
이 파이프라인은
성공한 적재만 명확히 기록하고,
폴더 구조 자체로 데이터 흐름이 설명되도록 설계된 ETL 구조입니다.
깃허브 주소: AnalyzeGit/marine_sensor_etl_pipeline: Apache Airflow 기반 해양 센서 데이터 자동 수집·처리·집계 ETL 파이프라인
GitHub - AnalyzeGit/marine_sensor_etl_pipeline: Apache Airflow 기반 해양 센서 데이터 자동 수집·처리·집계 ETL
Apache Airflow 기반 해양 센서 데이터 자동 수집·처리·집계 ETL 파이프라인. Contribute to AnalyzeGit/marine_sensor_etl_pipeline development by creating an account on GitHub.
github.com
'컨테이너·워크플로우 자동화 > Airflow로 워크플로우 자동화하기' 카테고리의 다른 글
| Airflow에서 Worker에만 pip 설치 가능한 경우의 해결 전략 (0) | 2026.02.24 |
|---|---|
| [프로젝트] Docker Compose 기반 Airflow와 PostgreSQL로 구성한 SQL 중심 ETL 파이프라인 (0) | 2026.02.09 |
| Airflow Task 상태를 기반으로 ETL 적재 성공·실패를 판단하는 방법 (0) | 2026.02.03 |
| Airflow PythonOperator에서 params로 값을 전달하고 함수에서 사용하는 방법 (0) | 2026.02.03 |
| trigger_rule="all_done" 이란 무엇인가 (0) | 2026.02.03 |