자동화된 선박 건강 모델 평가 프로세스
이전 블로그에서는 **통계 기반 건강 평가(apply_system_health_algorithms_with_total)**에 대해 다루었다. 이번에는 모델 학습 기반 건강 평가를 수행하는 apply_system_health_learning_algorithms_with_total 함수에 초점을 맞춰 설명한다. 해당 함수는 전처리된 데이터(preprocessed 데이터)를 입력받아 머신러닝 모델을 활용한 건강 평가를 수행하는 역할을 한다.
자동화된 데이터 필터링과 스케줄링 구축
데이터 분석 및 시스템 모니터링에서는 일정 주기로 데이터를 수집하고 처리하는 자동화된 파이프라인이 필수적이다. 이를 위해 DataFilterManager를 활용하여 데이터를 필터링하고, 특정 조건을 만
wnsgud4553.tistory.com
try:
sensor, preprocessed = distribute_by_application(ship_id=ship_id, op_index=op_index, section=section)
if sensor is None and preprocessed is None:
print("선박 데이터 프레임이 존재하지 않습니다.")
continue
elif preprocessed is not None:
logger.info(f'SHIP_ID={ship_id} | OP_INDEX={op_index} | SECTION={section} | START_TIME={date_time} | LOG_ENTRY=The results were derived from the model and statistics package | TYPE=all | IS_PROCESSED=True')
print("전처리 후 학습 데이터 프레임이 존재합니다.")
apply_system_health_algorithms_with_total(sensor, ship_id, op_index, section)
apply_system_health_learning_algorithms_with_total(data=preprocessed, ship_id=ship_id, op_index=op_index, section=section)
else:
logger.info(f'SHIP_ID={ship_id} | OP_INDEX={op_index} | SECTION={section} | START_TIME={date_time} | LOG_ENTRY=After preprocessing, the model data frame does not exist, so only the statistical algorithm proceeds alone | TYPE=stats | IS_PROCESSED=True')
print("전처리 후 모델 데이터 프레임이 존재하지 않아 통계 알고리즘 단독 진행합니다.")
apply_system_health_algorithms_with_total(data=sensor, ship_id=ship_id, op_index=op_index, section=section)
except ValueError as e :
logger.info(f'SHIP_ID={ship_id} | OP_INDEX={op_index} | SECTION={section} | START_TIME={date_time} | LOG_ENTRY={e} | TYPE=exceptional_handling | IS_PROCESSED=False')
print(f'에러 발생: {e}. 다음 반복으로 넘어갑니다.')
continue # 에러 발생 시 다음 반복으로 넘어감\
except KeyError as e :
logger.info(f'SHIP_ID={ship_id} | OP_INDEX={op_index} | SECTION={section} | START_TIME={date_time} | LOG_ENTRY={e} | TYPE=exceptional_handling | IS_PROCESSED=False')
print(f'에러 발생: {e}. 다음 반복으로 넘어갑니다.')
except TypeError as e :
logger.info(f'SHIP_ID={ship_id} | OP_INDEX={op_index} | SECTION={section} | START_TIME={date_time} | LOG_ENTRY={e} | TYPE=exceptional_handling | IS_PROCESSED=False')
print(f'에러 발생: {e}. 다음 반복으로 넘어갑니다.')
continue # 에러 발생 시 다음 반복으로 넘어감
except IndexError as e :
print(f'에러 발생: {e}. 다음 반복으로 넘어갑니다.')
logger.info(f'SHIP_ID={ship_id} | OP_INDEX={op_index} | SECTION={section} | START_TIME={date_time} | LOG_ENTRY={e} | TYPE=exceptional_handling | IS_PROCESSED=False')
continue # 에러 발생 시 다음 반복으로 넘어감
else:
logger.info(f'SHIP_ID={ship_id} | OP_INDEX={op_index} | SECTION={section} | START_TIME={date_time} | LOG_ENTRY=The data length is {data_len} and does not satisfy the condition | TYPE=data_length_limit | IS_PROCESSED=False')- 전처리된 데이터가 존재하는 경우
- apply_system_health_learning_algorithms_with_total()을 호출하여 학습 기반 알고리즘 실행
- 기존 통계 기반 평가(apply_system_health_algorithms_with_total)와 함께 실행되어 더 정교한 건강 평가 수행
- 전처리된 데이터가 없는 경우
- 머신러닝 모델을 활용할 수 없으므로 통계 기반 알고리즘만 실행
본 글에서는 apply_system_health_learning_algorithms_with_total 함수가 어떤 방식으로 학습 모델을 활용하고, 건강 평가를 수행하는지에 대해 구체적으로 설명하겠다.
DX_PROJECT 패키지 구조 설명
이 패키지는 건강 평가 및 모델 기반 분석을 수행하는 구조로 설계되어 있으며, 주요 구성 요소는 다음과 같다.

HealthModelPipeline/ (건강 평가 모델 파이프라인)
- dataflow/ → 데이터 흐름 및 모델 평가를 위한 핵심 폴더.
- scripts/ → 실행 관련 스크립트 파일 포함.
- src/ → 주요 소스 코드 디렉터리.
models_dataline/ (데이터 로드 및 관리)
- load_database.py → 데이터베이스에서 데이터를 가져오는 모듈.
- 건강 평가를 위해 필요한 데이터 불러오기 및 저장 역할 수행.
models_healthchecker/ (건강 평가 알고리즘 모듈)
- 선박 및 시스템의 건강 상태를 분석하는 다양한 알고리즘이 포함됨.
- deprecated_modules/ → 사용되지 않는 과거 모듈 보관.
- 주요 건강 평가 모듈:
- csu_system_health.py → CSU 기반 건강 평가
- current_system_health.py → 전류 기반 건강 평가
- fmu_system_health.py → FMU 기반 건강 평가
- fts_system_health.py → FTS 기반 건강 평가
- sts_system_health.py → STS 기반 건강 평가
- tro_fault_detector.py → TRO 이상 탐지
- rate_change_manager.py → 데이터 변화율 분석
- timeoffset_processor.py → 시간 오프셋 보정
models_model/ (건강 평가 머신러닝 모델 저장소)
- 건강 평가를 위한 머신러닝 모델 파일이 저장됨.
- 주요 모델:
- csu_model, csu_model_v2.0.0 → CSU 관련 모델
- fmu_model, fmu_model_v2.0.0 → FMU 관련 모델
- sts_model, sts_model_v2.0.0 → STS 관련 모델
- tro_group_model_v1.1.0, tro_group_model_v2.0.0 → TRO 이상 탐지 모델
- total_system_health.py → 종합적인 건강 평가 수행
modelup/src/ (추가적인 모델 관리 모듈)
- timemodel/ → 시간 기반 모델 관련 코드 포함 가능.
패키지 구조 핵심 정리
- models_dataline/ → 데이터 로드 및 저장 기능 담당
- models_healthchecker/ → 건강 평가 알고리즘 실행
- models_model/ → 머신러닝 모델을 활용한 건강 평가
- 기본적인 통계 기반 분석(models_healthchecker/)과 머신러닝 기반 평가(models_model/)가 결합된 구조로, 종합적인 건강 상태 분석을 수행.
이 구조를 통해 데이터 로드 → 건강 평가 알고리즘 적용 → 머신러닝 모델 분석 → 결과 저장의 전체적인 데이터 흐름이 자동화될 수 있도록 설계되어 있다.
apply_system_health_learning_algorithms_with_total 함수 설명
이 함수는 머신러닝 모델을 활용한 건강 평가 알고리즘을 실행하는 역할을 한다.
즉, 통계 기반 평가가 아닌, 학습된 모델을 이용하여 선박의 건강 상태를 분석하는 과정이다.
# basic
import pandas as pd
import time
# module.healthchecker
from .csu_system_health import ModelCsuSystemHealth
from .sts_system_health import ModelStsSystemHealth
from .fts_system_health import ModelFtsSystemHealth
from .fmu_system_health import ModelFmuSystemHealth
from .tro_fault_detector import TROFaultAlgorithm
from .current_system_health import ModelCurrentystemHealth
def time_decorator(func):
"""
함수의 실행 시간을 측정하는 데코레이터.
Args:
func (callable): 데코레이터가 적용될 함수.
Returns:
callable: 실행 시간을 측정하고 결과를 반환하는 래퍼 함수
"""
def wrapper(*args, **kwargs):
start_time = time.time() # 시작 시간 기록
result = func(*args, **kwargs) # 함수 실행
end_time = time.time() # 종료 시간 기록
print(f"{func.__name__} 함수 실행 시간: {end_time - start_time:.4f}초")
return result
return wrapper
@time_decorator
def apply_system_health_learning_algorithms_with_total(data: pd.DataFrame, ship_id: str) -> None:
"""
시스템 건강 알고리즘을 순차적으로 적용하는 함수.
Args:
data (pd.DataFrame): 입력 데이터 프레임.
ship_id (str): 선박 ID.
op_index (int): 작업 인덱스.
section (str): 섹션 정보.
"""
# 클래스와 메서드 정의를 리스트로 관리
algorithms = [
(ModelCsuSystemHealth, "apply_system_health_algorithms_with_csu"),
(ModelStsSystemHealth, "apply_system_health_algorithms_with_sts"),
(TROFaultAlgorithm, "apply_tro_fault_detector"),
(ModelFtsSystemHealth, "apply_system_health_algorithms_with_fts"),
(ModelFmuSystemHealth, "apply_system_health_algorithms_with_fmu"),
(ModelCurrentystemHealth, "apply_system_health_algorithms_with_current")
]
for model_class, method_name in algorithms:
if method_name == 'apply_system_health_algorithms_with_fmu':
instance = model_class(data, ship_id=ship_id)
else:
instance = model_class(data)
getattr(instance, method_name)(status=True)실행되는 주요 알고리즘 (모델 기반 건강 평가)
다양한 시스템 건강 평가 모델이 적용되며, 사용되는 클래스는 다음과 같다.
- ModelCsuSystemHealth → CSU 시스템 건강 평가
- ModelStsSystemHealth → STS 시스템 건강 평가
- TROFaultAlgorithm → TRO 센서 이상 탐지
- ModelFtsSystemHealth → FTS 시스템 건강 평가
- ModelFmuSystemHealth → FMU 기반 건강 평가
- ModelCurrentSystemHealth → 전류 기반 건강 평가
각 클래스는 해당 시스템의 데이터를 학습된 모델을 이용하여 분석하고, 건강 상태를 평가하는 기능을 수행한다.
실행 흐름
- 알고리즘 리스트(algorithms) 정의
- 각 건강 평가 모델의 클래스와 메서드를 리스트로 저장.
- 각 모델의 건강 평가 실행
- 리스트에 저장된 모델을 순회하면서 동적으로 인스턴스를 생성하고 평가 메서드를 실행.
- getattr(instance, method_name)(status=True)을 사용하여 메서드를 문자열로 받아 실행.
- FMU 모델 예외 처리
- apply_system_health_algorithms_with_fmu는 ship_id를 추가로 입력해야 하므로 별도로 처리.
- 모든 알고리즘 실행 후 건강 상태 평가 완료
핵심 특징
- 머신러닝 모델을 활용하여 건강 평가 수행.
- getattr()을 이용한 동적 메서드 호출로 코드 간결화.
- CSU, STS, FMU 등 개별 시스템의 건강 상태를 모델을 통해 분석.
이 함수를 통해 전처리된 데이터가 학습된 모델을 기반으로 평가되며, 각 시스템의 건강 상태를 예측하고 이상 여부를 판단하는 과정이 자동으로 수행된다.
모델 기반 건강 평가 시스템: 베이스 클래스 상속 및 자동 데이터 적재
이 시스템은 통계 기반 알고리즘과 머신러닝 모델을 활용한 건강 평가를 수행하며, 두 가지 방식 모두 베이스 클래스를 상속받아 일관된 구조로 설계되어 있다. 또한, 예측된 건강 평가 데이터는 자동으로 적재되며, 차후 학습 데이터로 활용될 수 있도록 설계되었다.


베이스 클래스(BaseFaultAlgorithm) 상속 구조
- 통계 기반 알고리즘 (TROFaultAlgorithm 등)
- BaseFaultAlgorithm을 상속받아 공통적인 데이터 정리 및 전처리 로직을 활용.
- categorize_health_score()를 통해 건강 점수를 기반으로 NORMAL, WARNING, RISK, DEFECT로 분류.
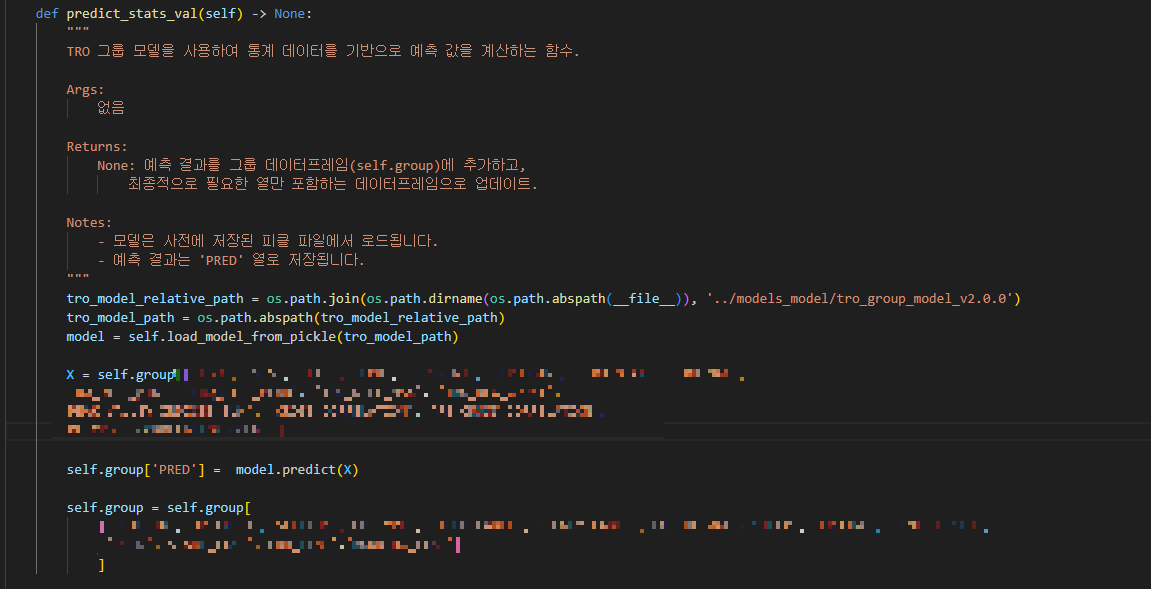
- 모델 기반 예측 (predict_stats_val())
- tro_group_model_v2.0.0을 불러와 학습된 머신러닝 모델을 사용하여 TRO 관련 건강 점수 예측.
- BaseFaultAlgorithm을 상속받아 데이터 처리 방식의 일관성을 유지.
- 모델 모듈 (apply_system_health_learning_algorithms_with_total)
- ModelCsuSystemHealth, ModelFmuSystemHealth 등은 베이스 클래스를 상속받아 머신러닝 기반 건강 평가 수행.
- getattr(instance, method_name)(status=True)을 통해 동적으로 모델 평가 실행.
건강 평가 예측 데이터 자동 적재
- predict_stats_val() 실행 후, 예측 결과(PRED 컬럼)는 self.group 데이터프레임에 저장.
- 이후 해당 데이터는 자동으로 적재되어 향후 모델 학습 데이터로 활용 가능.
- load_database() 또는 data pipeline을 통해 저장소(ecs_test 등)에 기록될 가능성이 있음.
시스템의 주요 특징
✅ 일관된 코드 구조 → 통계 알고리즘과 모델 모듈 모두 BaseFaultAlgorithm을 상속받아 공통된 데이터 처리 방식을 유지.
✅ 자동 적재 기능 → 건강 평가 결과는 자동으로 저장되어 향후 학습 데이터로 활용 가능.
✅ 확장성 보장 → 새로운 알고리즘이나 모델이 추가되더라도 기존 구조를 유지하면서 쉽게 확장 가능.
✅ 통합된 건강 평가 시스템 → 통계적 분석과 머신러닝 예측을 결합하여 보다 정밀한 선박 건강 상태 분석 가능.
결론
이 시스템은 베이스 클래스를 적극 활용하여 코드의 일관성과 확장성을 보장하며, 예측된 건강 평가 데이터는 자동으로 적재되어 차후 학습 데이터로 활용될 수 있도록 설계되었다. 이를 통해 데이터 수집 → 건강 평가 → 예측 → 자동 저장의 흐름이 완성되며, 선박의 상태를 지속적으로 학습하고 개선할 수 있는 데이터 파이프라인이 구축된다.